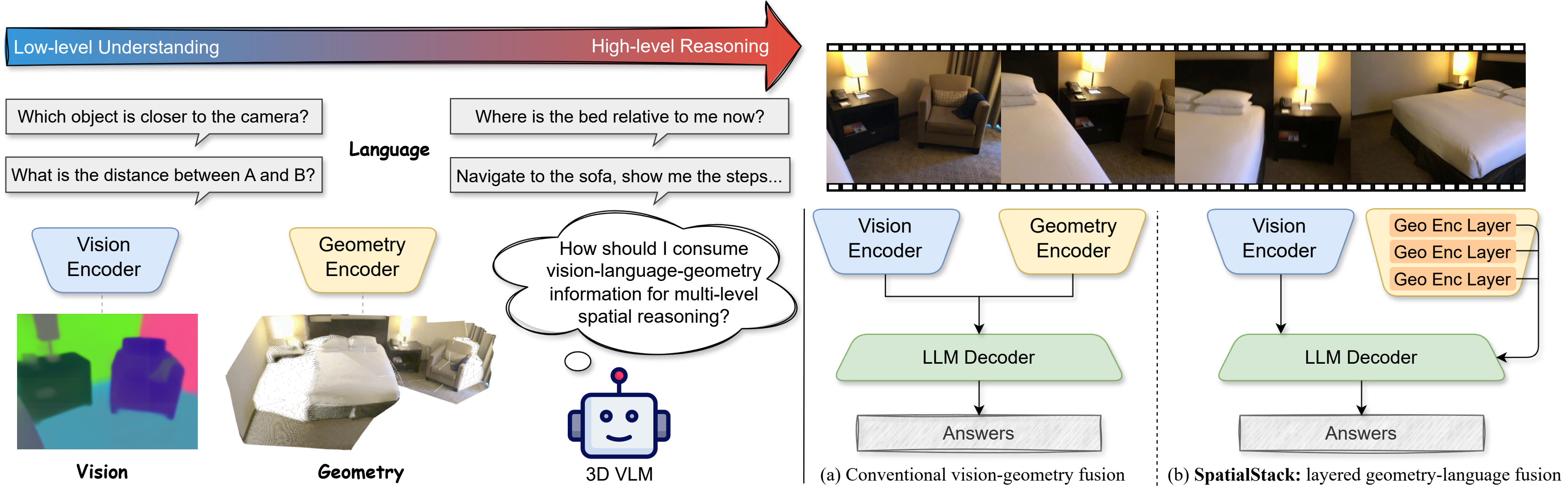
Large vision-language models (VLMs) still struggle with reliable 3D spatial reasoning, a core capability for embodied and physical AI systems. This limitation arises from their inability to capture fine-grained 3D geometry and spatial relationships. While recent efforts have introduced multi-view geometry transformers into VLMs, they typically fuse only the deep-layer features from vision and geometry encoders, discarding rich hierarchical signals and creating a fundamental bottleneck for spatial understanding.
To overcome this, we propose SpatialStack, a general hierarchical fusion framework that progressively aligns vision, geometry, and language representations across the model hierarchy. Moving beyond conventional late-stage vision-geometry fusion, SpatialStack stacks and synchronizes multi-level geometric features with the language backbone, enabling the model to capture both local geometric precision and global contextual semantics. Building upon this framework, we develop VLM-SpatialStack, a model that achieves state-of-the-art performance on multiple 3D spatial reasoning benchmarks. Extensive experiments and ablations demonstrate that our multi-level fusion strategy consistently enhances 3D understanding and generalizes robustly across diverse spatial reasoning tasks, establishing SpatialStack as an effective and extensible design paradigm for vision-language-geometry integration in next-generation multimodal physical AI systems.
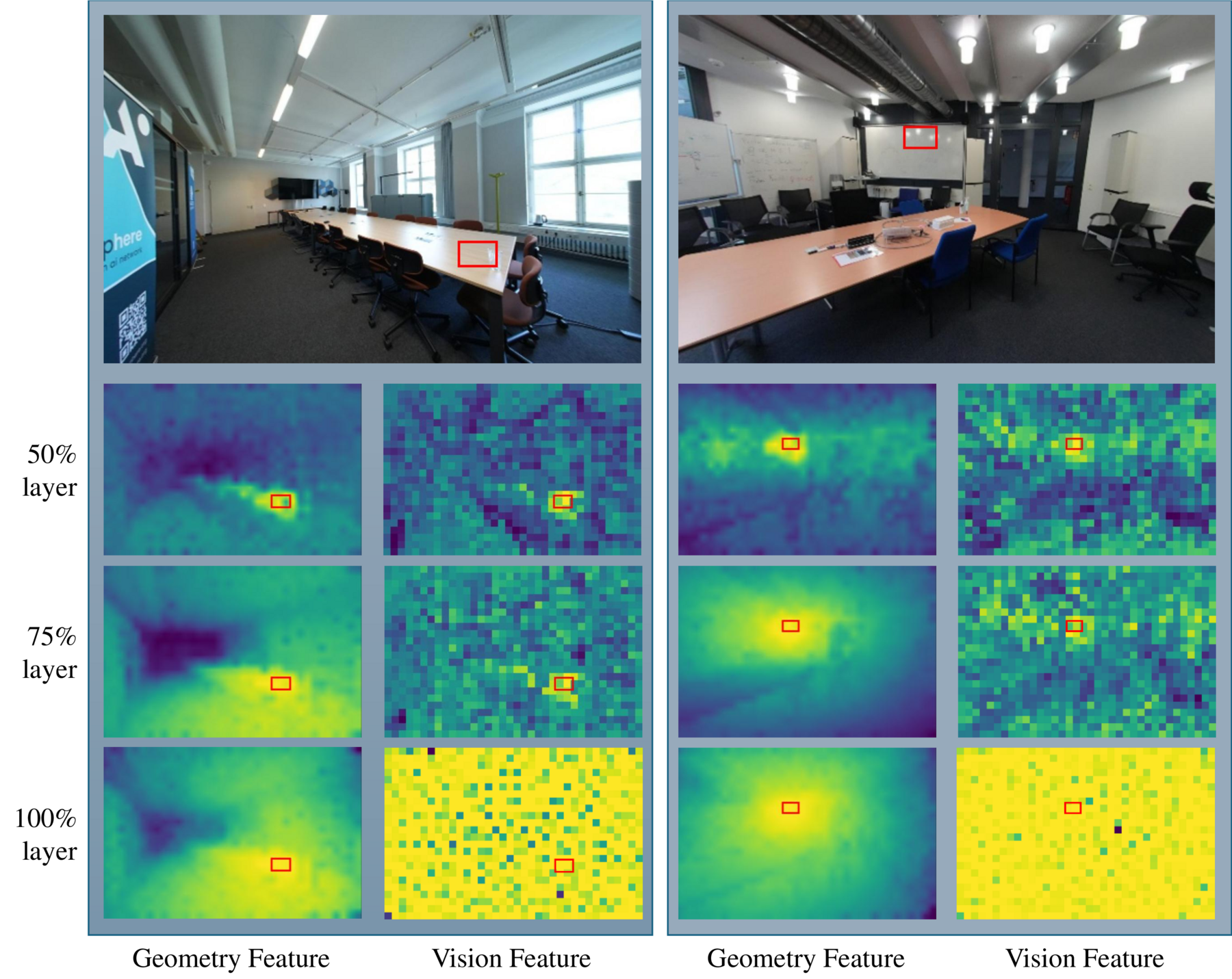
SpatialStack stacks geometry tokens because the geometry stream preserves ROI structure across encoder depths, while vision features become noisy and nearly uniform at deeper layers, motivating hierarchical geometry-language fusion.
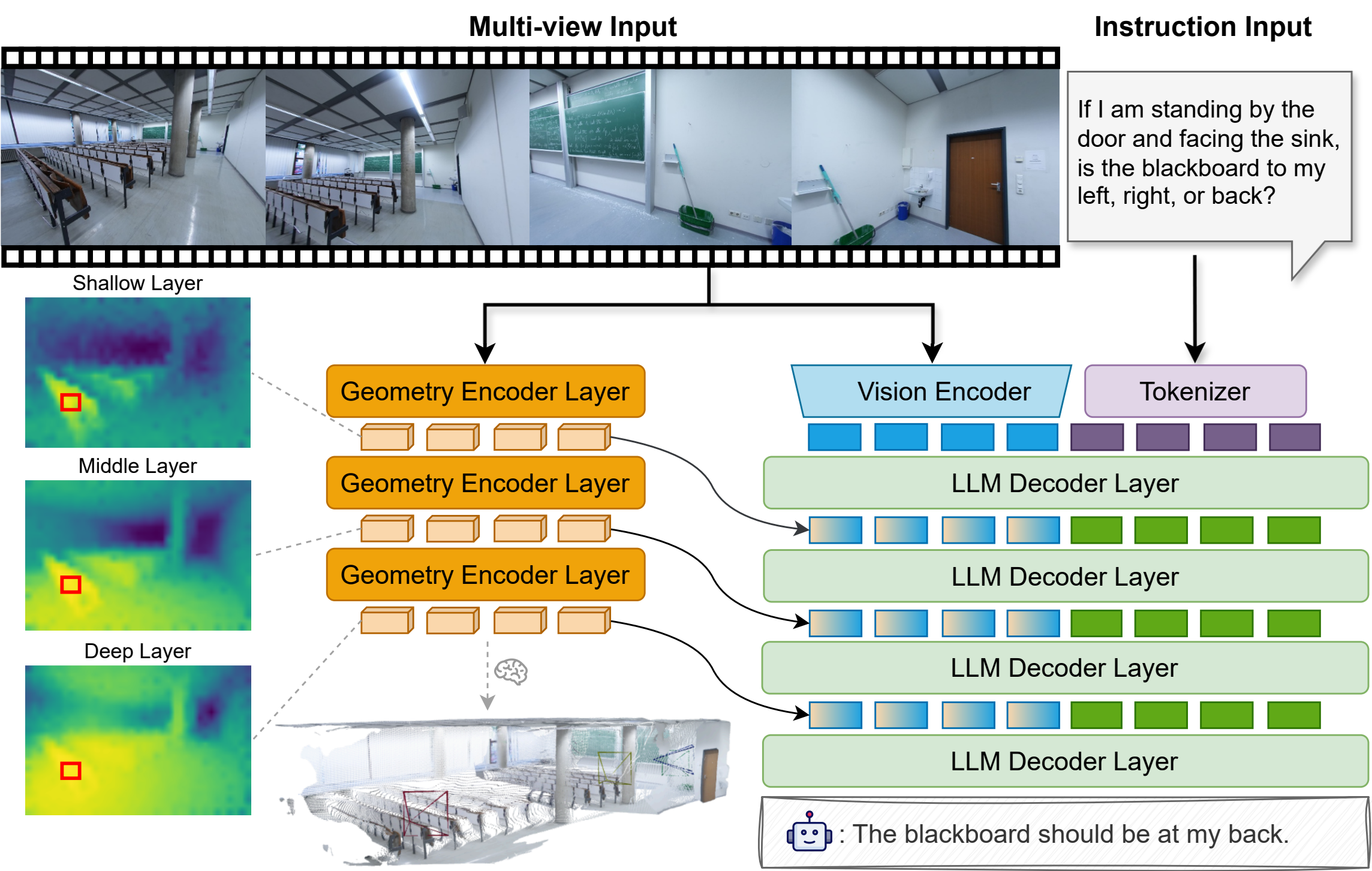
SpatialStack keeps the vision encoder unchanged and augments the language decoder with a parallel VGGT geometry stream. Geometry tokens from several semantic depths are compressed by lightweight mergers and injected as residual adapters throughout the decoder, so each stage reasons over aligned visual, geometric, and textual cues while preserving both local structure and global scene context.
| Model | Rank | Avg | Obj Count | Abs Dist | Obj Size | Room Size | Rel Dist | Rel Dir | Route Plan | Appr Order |
|---|---|---|---|---|---|---|---|---|---|---|
| LongVILA-8B | 14 | 21.6 | 29.1 | 9.1 | 16.7 | 0.0 | 29.6 | 30.7 | 32.5 | 25.5 |
| Qwen2.5-VL-3B | 13 | 28.7 | 33.1 | 19.4 | 17.4 | 24.8 | 37.3 | 44.3 | 31.4 | 22.0 |
| VILA-1.5-8B | 12 | 28.9 | 17.4 | 21.8 | 50.3 | 18.8 | 32.1 | 34.8 | 31.0 | 24.8 |
| LongVA-7B | 11 | 29.2 | 38.0 | 16.6 | 38.9 | 22.2 | 33.1 | 43.3 | 25.4 | 15.7 |
| Qwen2.5-VL-7B | 10 | 29.2 | 25.2 | 10.9 | 35.8 | 29.2 | 38.7 | 37.5 | 29.4 | 26.7 |
| VILA-1.5-40B | 9 | 31.2 | 22.4 | 24.8 | 48.7 | 22.7 | 40.5 | 25.7 | 31.5 | 32.9 |
| LLaVA-OneVision-7B | 8 | 32.4 | 47.7 | 20.2 | 47.4 | 12.3 | 42.5 | 35.2 | 29.4 | 24.4 |
| LLaVA-Video-7B | 7 | 35.6 | 48.5 | 14.0 | 47.8 | 24.2 | 43.5 | 42.4 | 34.0 | 30.6 |
| LLaVA-OneVision-72B | 6 | 40.2 | 43.5 | 23.9 | 57.6 | 37.5 | 42.5 | 39.9 | 32.5 | 44.6 |
| LLaVA-Video-72B | 5 | 40.9 | 48.9 | 22.8 | 57.4 | 35.3 | 42.4 | 36.7 | 35.0 | 48.6 |
| Spatial-MLLM-4B | 4 | 47.0 | 65.3 | 34.8 | 63.1 | 45.1 | 41.3 | 46.2 | 33.5 | 46.3 |
| VG-LLM-4B | 3 | 47.3 | 66.0 | 37.8 | 55.2 | 59.2 | 44.6 | 45.6 | 33.5 | 36.4 |
| Cambrian-S-3B | 2 | 57.3 | 70.7 | 40.6 | 68.0 | 46.3 | 64.8 | 61.9 | 27.3 | 78.8 |
| SpatialStack-4B | 1 | 60.9 | 69.2 | 45.4 | 63.0 | 63.2 | 57.9 | 68.4 | 40.2 | 79.6 |
VSI-Bench leaderboard. SpatialStack-4B reaches the top open-source average (60.9) and leads most sub-tasks.
VSI-Bench spans more than 5,000 egocentric QA pairs across eight categories: four numerical tasks (object count, absolute distance, object size, room size) and four multiple-choice tasks (relative distance, relative direction, route planning, appearance order). Despite having no route-planning supervision, SpatialStack generalizes strongly to that category while remaining competitive on the rest of the benchmark.
| Model | 2D (%) | 3D (%) | Avg. (%) |
|---|---|---|---|
| Proprietary Models (API) | |||
| GPT-4o | 74.8 | 83.0 | 78.9 |
| Open-source Models | |||
| Mini-Gemini-HD-34B | 71.5 | 79.2 | 75.4 |
| LLaVA-NeXT-34B | 73.0 | 74.8 | 73.9 |
| Cambrian-1-34B | 74.0 | 79.7 | 76.9 |
| SAT-LLaVA-Video-7B | 73.0 | 83.8 | 78.4 |
| SPAR-8B | 72.3 | 89.1 | 80.7 |
| Qwen2.5-VL-3B | 67.9 | 70.4 | 69.2 |
| Qwen2.5-VL-7B | 73.9 | 80.9 | 77.4 |
| Cambrian-S-7B | 74.3 | 83.0 | 78.7 |
| Cambrian-S-3B | 76.1 | 76.3 | 76.2 |
| Dual-Encoder MLLMs | |||
| VG-LLM-4B | 71.3 | 87.7 | 79.5 |
| VG-LLM-8B | 72.2 | 91.1 | 81.7 |
| SpatialStack-4B | 75.4 | 87.0 | 81.2 |
| SpatialStack-8B | 76.1 | 90.8 | 83.5 |
CV-Bench leaderboard. SpatialStack-4B and -8B outperform existing dual-encoder baselines across splits.
CV-Bench reformulates classical 2D relation/counting tasks and 3D depth/distance questions into QA evaluations. SpatialStack-4B already overtakes VG-LLM-4B on both splits, while SpatialStack-8B delivers the best overall accuracy (83.5) and matches the strongest reported 2D score.